Routine inspection is a foundational element of data center facility operations. It plays a critical role in uncovering hidden risks, preventing incidents, and ensuring business continuity. As automation grows and organizations push for efficiency, inspections must evolve from “routine walk-arounds” to a more trend-driven, risk-focused, and early-warning approach.
In globally recognized data center operation standards, inspections, together with monitoring, alarms, and incident response, form the first line of defense. Their value lies in detecting trends, understanding environmental conditions, and validating changes to capture potential risks before they become problems. Here are six priorities that modern inspections should emphasize.
1. Focus on Trends, Not Just Single Data Points
Many facilities still rely on manual readings to judge whether equipment is “normal.” But the true insight lies in trend analysis. Equipment degradation usually develops gradually and often does not trigger alarms in the early stage.
Typical examples include:
Trend-based inspection shifts the practice from data recording to predictive warning.
2. Use Human Perception to Fill Sensor Blind Spots
Sensors cannot capture everything. Human senses remain an irreplaceable “last line of defense.” Trained personnel can detect abnormalities through sight, sound, smell, and touch.
Metallic odor may indicate poor electrical contact or arcing; burning smells often signal cable overheating; a sulfur odor may stem from battery overcharge; diesel smell could indicate fuel leakage.
Unusual vibration, humming, or friction noises from UPS units, CRACs, or pumps often relate to bearing wear, loose fasteners, or resonance issues.
Water marks, swollen batteries, abnormal condensation, or pooling water are early signs of underlying issues.
Humans can detect hotspot changes and airflow direction shifts that sensors may miss entirely.
Human-based inspection enables early-stage intervention long before faults surface in monitoring systems.
3. Special Inspections After Business Changes
The period right after a service goes online or offline is one of the highest-risk windows. This is why international O&M standards commonly require joint inspection within 24 hours after any major change.
Validate power load distribution, cable temperature, PDU balance, local hotspots, and cooling adequacy.
Verify resource release, equipment cleanup, and asset reconciliation to avoid “hidden assets” and residual risks.
Post-change inspection serves as a second validation layer, ensuring operational stability under the new configuration.
4. Reassess Risk After System-Level Changes
Single-device testing after upgrades or parameter adjustments may overlook integration risks. Inspections must confirm:
This step ensures upgrades do not introduce new vulnerabilities.
5. Prioritize High-Risk Areas and Monitoring Blind Spots
Inspections should focus on zones that carry high inherent risk or where sensors cannot fully cover conditions.
Such areas reflect the depth and professionalism of O&M practices.
6. Apply Seasonal Inspection Strategies
Inspection priorities must adapt to seasonal environmental changes and be planned using historical data.
Seasonal inspection is a critical part of annual risk management.
Turning Inspections into Operational Intelligence
Inspections are no longer simply routine tasks; they are a key tool for managing data center risk and supporting operational resilience. By monitoring trends, leveraging human observation, validating changes, focusing on high-risk areas, and adapting to seasonal conditions, operations teams can transform inspections into actionable intelligence. This approach helps prevent hidden problems, strengthen system reliability, and ensure continuous business operations.
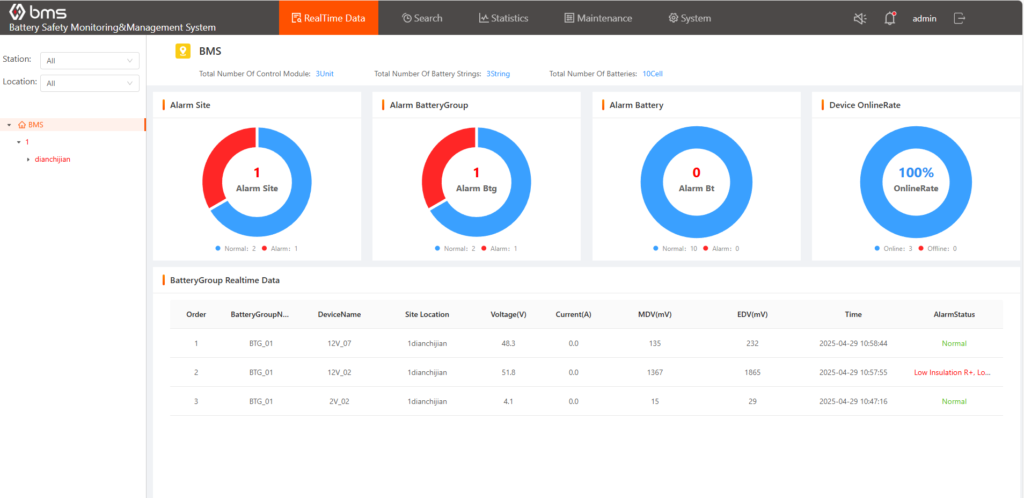
Apply a demo of Gerchamp’s Cloud Platform
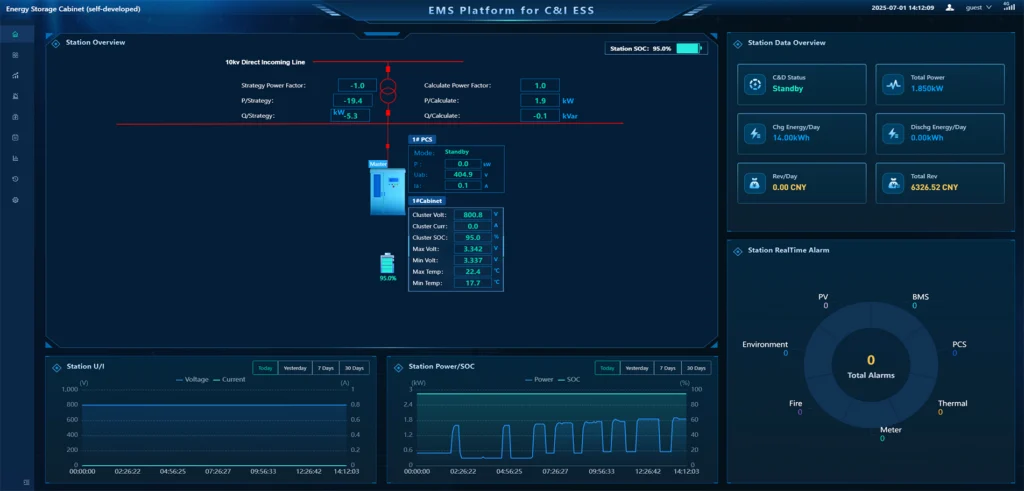
Apply a demo of Gerchamp’s Cloud Platform